10月29日にStability AIよりStable Diffusion 3.5 Mediumがリリースされました。Stable Diffusion 3.5ではStable Diffusion 3.0で不要だったライセンス周りが改善されたため、さっそく導入して使用してみましたのでご紹介します。
Stable Diffusion 3.5で改善された点
ライセンス周り
Stable Diffusion 3.5ではStable Diffusion 3.0と比較してライセンス周りがかなり変更され、使いやすくなりました。簡単に言うとStable Diffusion 3.0ではお金を払わないと商用利用ができなかったのに対して、Stable Diffusion 3.5では年間収益が100万ドル以下であれば無料で商用利用が可能になりました。
生成できる画像のクオリティ向上
Stable Diffusion 3.5ではLargeで80億のパラメータ、Meduimでも26億のパラメータをもっています。※パラメータ数が多いほど、モデルはより複雑なパターンを学習し、より高品質な画像を生成できる
Stable Diffusionの初期バージョンである1.4ではこのパラメータ数は8億ほどだったため、Largeでは10倍に進化しているということですね。

Stable Diffusion 3.5 Mediumのメリット
Stable Diffusion 3.5ではLarge、Large Turbo、Mediumの3つのバージョンがリリースされていますが、今回Mediumを試してみた理由は要求されるマシンスペックが低いというメリットがあったからです。
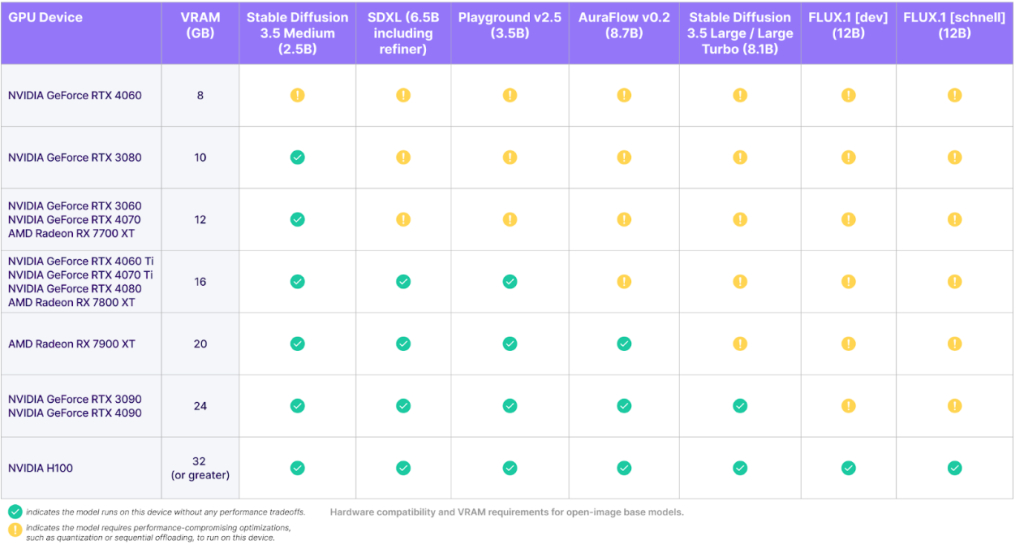
以下がStability AIから公開されている必要なGPUの比較表です。Large、Large TurboではNVIDIA GeForce RTX 3090/4090 VRAM24GB以上が必要なのに対して、MediumはNVIDIA GeForce RTX 3080以上で動作します。私の環境はNVIDIA GeForce RTX 3060 VRAM12GBなのでAIガチ勢ではない環境でも動作するのは非常にありがたいですね。
Stable Diffusion 3.5 Mediumのローカル環境を構築
はじめに
現状Stable Diffusion 3.5 Mediumをローカル環境で使用するには、前提としてComfy UIを使える状態にしておく必要があります。以下の動画が非常に分かりやすく解説してくれていましたので、こちらを参考にさせていただきました。
| 私はすでにStable Diffusion Web UI AUTOMATIC1111版(Comfy UIとは異なるStable Diffusionを使うためのUI)を使っていたので、動画8:30あたりからの「通常ローカル環境の場合」を参考にして導入しましたが、これからStable Diffusionを使い始める方は前半の「Stability Matrixの場合」を参考に導入したほうが簡単だと思います。 |
必要なファイルのダウンロード
Comfy UIの準備ができたらHugging faceから必要なファイルをダウンロードしましょう。必要なファイルは次の5つです。
また、ComfyUI_examplesにあるサンプル画像を保存しておきます。
ダウンロードしたファイルの配置
ダウンロードしたファイルをそれぞれ次の場所に保存します。
| ComfyUIがインストールされているフォルダ¥ComfyUI_windows_portable_nvidia\ComfyUI_windows_portable\ComfyUI\models\checkpoints |
| ComfyUIがインストールされているフォルダ¥ComfyUI_windows_portable_nvidia\ComfyUI_windows_portable\ComfyUI\models\clip |
- ComfyUI_examplesにあるサンプル画像
| どこでもOK |
Comfy UIの実行
ComfyUIがインストールされているフォルダ¥ComfyUI_windows_portable_nvidia\ComfyUI_windows_portable\にあるrun_nvidia_gpu.batを実行してComfy UIを立ち上げます。
このようなWeb UIが立ち上がります。
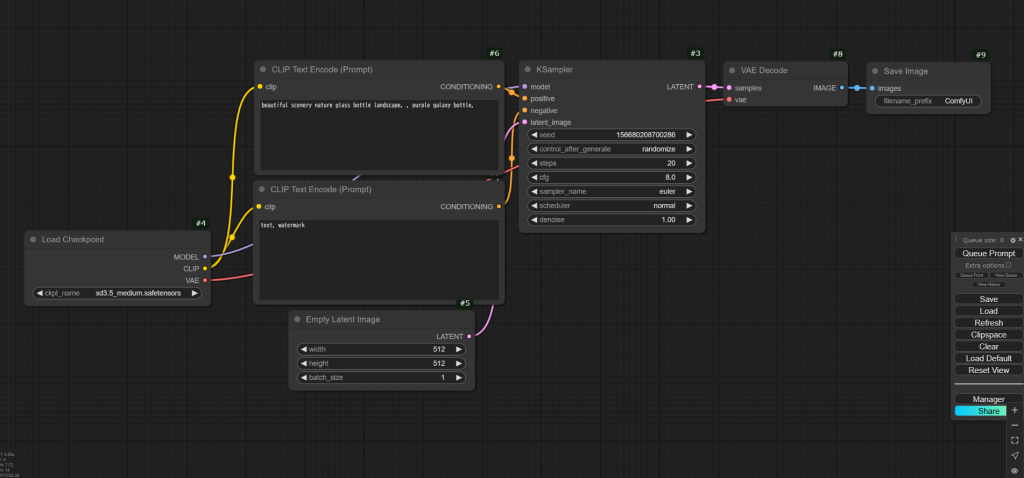
保存しておいたサンプル画像を画面上にドラッグ&ドロップで持ってくると、このようにワークフローが変わります。
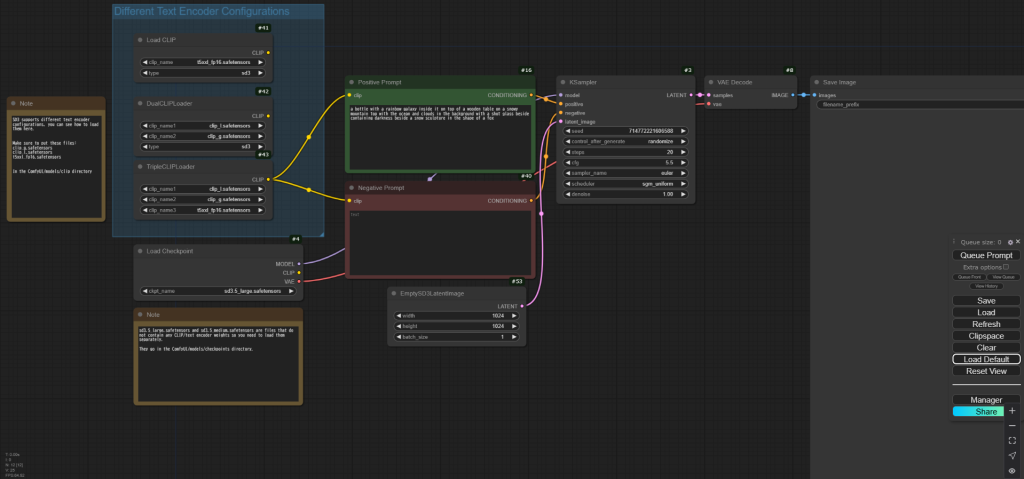
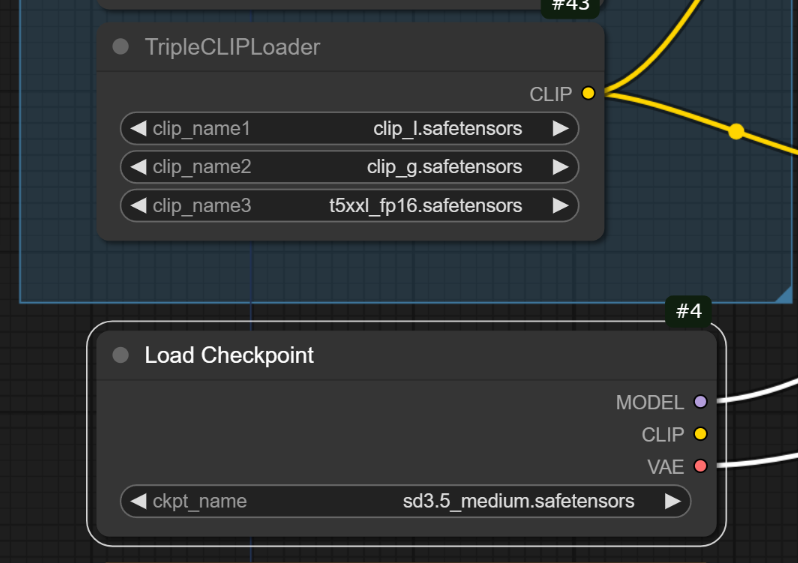
以下の4か所を画像のようにダウンロードしてきたStable Diffusion 3.5 Medium用のファイルに変更します。※もし選択しても変更できない場合はファイルが保存されている場所が間違っている可能性があります。
[Queue Prompt]を実行すると画像生成が開始されます。
このようにサンプル画像に似た画像さ生成されました。
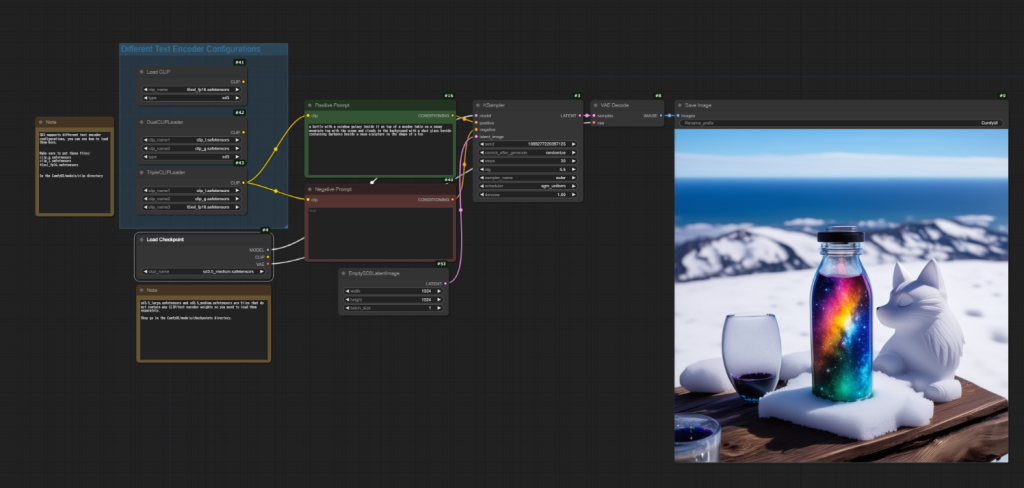
私がよく作る人物画像だとこんな感じでした。日本人に適したモデルを使わなくてもしっかり日本人風の人物が生成されたので期待できそうです。
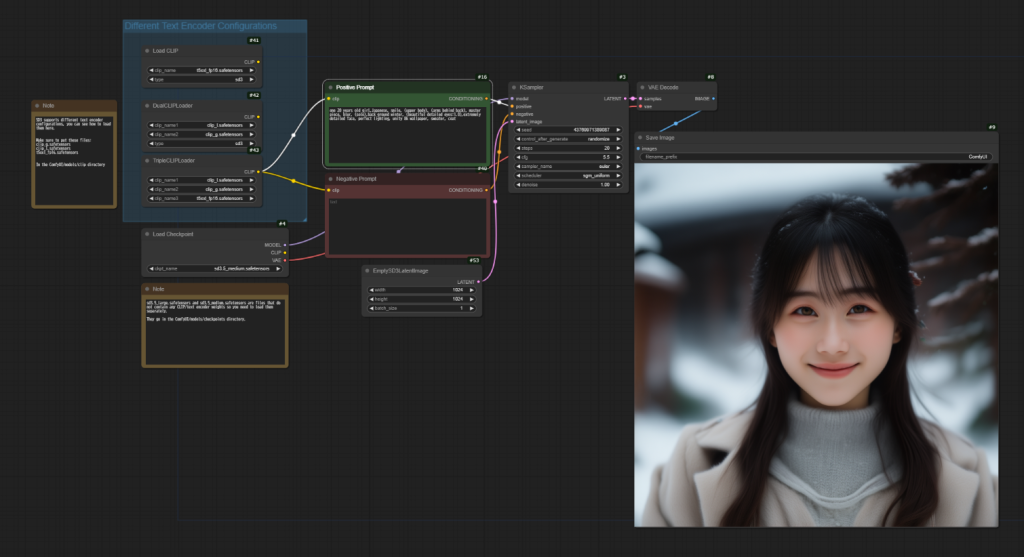
これまでStable Diffusion 1.7を使ってきましたが、今後はStable Diffusion 3.5 Mediumを使ってより高品質の画像が作成できるか試行錯誤してみたいと思います。
補足(つまずいた点)
初め[Queue Prompt]を実行してもワークフローが進まず以下のエラーが出力されました。
| Error(s) in loading state_dict for OpenAISignatureMMDITWrapper: size mismatch for joint_blocks.0.x_block.adaLN_modulation.1.weight |
\ComfyUI_windows_portable_nvidia\ComfyUI_windows_portable\updateにあるupdate_comfyui_and_python_dependencies.batを実行し、ComfyUI の依存関係を再インストールすることで解決しました。
宣伝(PR)
生成AIで作成した画像を公開しています。高画質版はPIXTAやAdobe Stockで販売しておりますので、よろしければこちらもご覧ください。